Metadata is communication; it can tell a story about research and paint a picture for others to respond to and learn from, across the world and throughout the forthcoming generations. Metadata can feel technical with words like ‘infrastructure’ and ‘schema’, and sometimes, like tech in general, it comes with hyperbole. But metadata really is part art (storytelling and pictures) and part science (structured models and standards) with both aspects being equally important, and requiring people as well as systems. That necessary combination of human and machine involvement also makes metadata challenging.
Once a year we release all metadata records for content registered with Crossref in a public data file. This year’s version, containing nearly 180 million records, is now available. It includes metadata associated with all Crossref-registered DOIs in JSON-lines format.
Crossref Ambassadors act as local points of contact, meeting editors, librarians, researchers, and institutions to help them navigate Crossref services and understand how strong metadata supports visibility, integrity, and trust in research. They explain how to participate in our rich network of connections between works, people, and institutions, in ways that make sense in their own contexts. And last year, being our 25th anniversary, Ambassadors also massively contributed to our celebrations!
We have renewed our partnership with DOAJ to focus on a new set of objectives that reflect both organisations’ commitment to improving sustainable and equitable services and infrastructure. This renewed collaboration focuses on improving the quality of scholarly metadata while expanding support for journals in low- and middle income- countries.
We have worked together since 2021, primarily to encourage the dissemination and use of scholarly research using online technologies, and regional and international networks, partners and communities. This partnership has helped to build local institutional capacity and sustainability within the global scholarly communication ecosystem. A continued partnership also reflects that we have a shared community; currently almost 90% of DOAJ journals are represented in Crossref.
It’s here. After years of hard work and with a huge cast of characters involved, I am delighted to announce that you will now be able to instantly link to all published articles related to an individual clinical trial through the Crossmark dialogue box. Linked Clinical Trials are here!
In practice, this means that anyone reading an article will be able to pull a list of both clinical trials relating to that article and all other articles related to those clinical trials – be it the protocol, statistical analysis plan, results articles or others – all at the click of a button.
Linked Clinical Trials interface
Now I’m sure you’ll agree that this sounds nifty. It’s definitely a ‘nice-to-have’. But why was it worth all the effort? Well, simply put: “to move a mountain, you begin by carrying away the small stones”.
Science communication in its current form is an anachronism, or at the very least somewhat redundant.
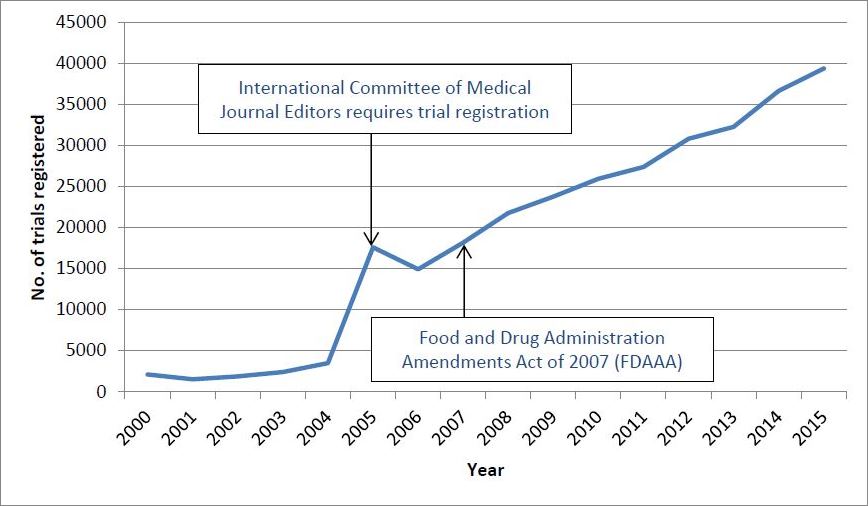
You may have read about the ‘crisis in reproducibility’. Good science, at its heart, should be testable, falsifiable and reproducible, but an historical over-emphasis on results has led to a huge number of problems that seriously undermine the integrity of the scientific literature.
Issues such as publication bias, selective reporting of outcome and analyses, hypothesising after the results are known (HARKing) and p-hacking are widespread, and can seriously distort the literature base (unless anyone seriously considers Nicholas Cage to be causally related to people drowning in swimming pools).
This is, of course, nothing new. Calls for prospective registration of clinical trials date back to the 1980s and it is now becoming increasingly commonplace, recognising that the quality of research lies in the questions it asks and the methods it uses, not the results observed.
Uptake of trial registration year-on-year since 2000
Building on this, a number of journals and funders – starting with BioMed Central’s Trialsover 10 years ago – have also pushed for the prospective publication of a study’s protocol and, more recently, statistical analysis plan. The idea that null and non-confirmatory results have value and should be published has also gained increasing support.
Over the last ten years, there has been a general trend towards increasing transparency. So what is the problem? Well, to borrow an analogy from Jeremy Grimshaw, co-Editor-in-Chief of Trials – we’ve gone from Miró to Pollock.
Although a results paper may reference a published study protocol, there is nothing to link that report to subsequent published articles; and no link from the protocol itself to the results article.
A single clinical trial can result in multiple publications: the study protocol and traditional results paper or papers, as well as commentaries, secondary analyses and, eventually, systematic reviews, among others, many published in different journals, years apart. This situation is further complicated by an ever-growing body of literature.
Researchers need access to all of these articles if they are to reliably evaluate bias or selective reporting in a research object, but – as any systematic reviewer can tell you – actually finding them all is like looking for a needle in a haystack. When you don’t know how many needles there are. With the haystack still growing.
That’s where we come in. The advent of trial registration means that there is a unique identifier associated with every clinical trial, at the study-level, rather than the article level. Building on this, the Linked Clinical Trials project set out to connect all articles relating to an individual trial together using its trial registration number (TRN).
By adapting the existing Crossmark standard, we have captured additional metadata about an article, namely the TRN and the trial registry, with this information then associated with the article’s DOI on publication. This means that you will be able to pull all articles related to an individual clinical trial from the Crossmark dialogue box on any relevant article.
This obviously has huge implications for the way science is reported and used. By quickly and easily linking to related published articles, it will enable editors, reviewers and researchers to evaluate any selective reporting in the study, and help to provide far greater context for the results.
As all the metadata will be open access (CC0), with no copyright, it will also be possible to access this article ‘thread’ through the Crossref Metadata Search, or independently through an application programming interface (API). This provides a platform for others to build on, with many already looking to take the next step, such as Ben Goldacre’s new Open Trials initiative.
However, in order for this to work, we must capture as many articles and trials as possible to create a truly comprehensive thread of publications. We currently have data from the NIHR Libraries, PLoS and, of course, BioMed Central, but need more publishers and journals to join us in depositing clinical trial metadata. After all, without metadata, this is all merely wishful thinking.
Let’s hope we’re the pebble that starts the landslide.