We’re excited to announce a new data citation API endpoint and are seeking your feedback. The new service makes existing data citation relationships in our metadata available, thereby surfacing this part of the research nexus. At the same time, we’ve decided that it’s time to move on from Event Data.
Metadata is communication; it can tell a story about research and paint a picture for others to respond to and learn from, across the world and throughout the forthcoming generations. Metadata can feel technical with words like ‘infrastructure’ and ‘schema’, and sometimes, like tech in general, it comes with hyperbole. But metadata really is part art (storytelling and pictures) and part science (structured models and standards) with both aspects being equally important, and requiring people as well as systems. That necessary combination of human and machine involvement also makes metadata challenging.
Once a year we release all metadata records for content registered with Crossref in a public data file. This year’s version, containing nearly 180 million records, is now available. It includes metadata associated with all Crossref-registered DOIs in JSON-lines format.
Crossref Ambassadors act as local points of contact, meeting editors, librarians, researchers, and institutions to help them navigate Crossref services and understand how strong metadata supports visibility, integrity, and trust in research. They explain how to participate in our rich network of connections between works, people, and institutions, in ways that make sense in their own contexts. And last year, being our 25th anniversary, Ambassadors also massively contributed to our celebrations!
Many researchers want to carry out analysis and extraction of information from large sets of data, such as journal articles and other scholarly content. Methods such as screen-scraping are error-prone, place too much strain on content sites and may be unrepeatable or break if site layouts change. Providing researchers with automated access to the full-text content via DOIs and Crossref metadata reduces these problems, allowing for easy deduplication and reproducibility. Supporting text and data mining echoes our mission to make research outputs easy to find, cite, link, assess, and reuse.
In 2013 Crossref embarked on a project to better support Crossref members and researchers with Text and Data Mining requests and access. There were two main parts to the project:
To collect and make available full-text links and publisher TDM license links in the metadata.
To provide a service (TDM click-through service) for Crossref members to post their additional TDM terms and conditions and for researchers to access, review and accept these terms.
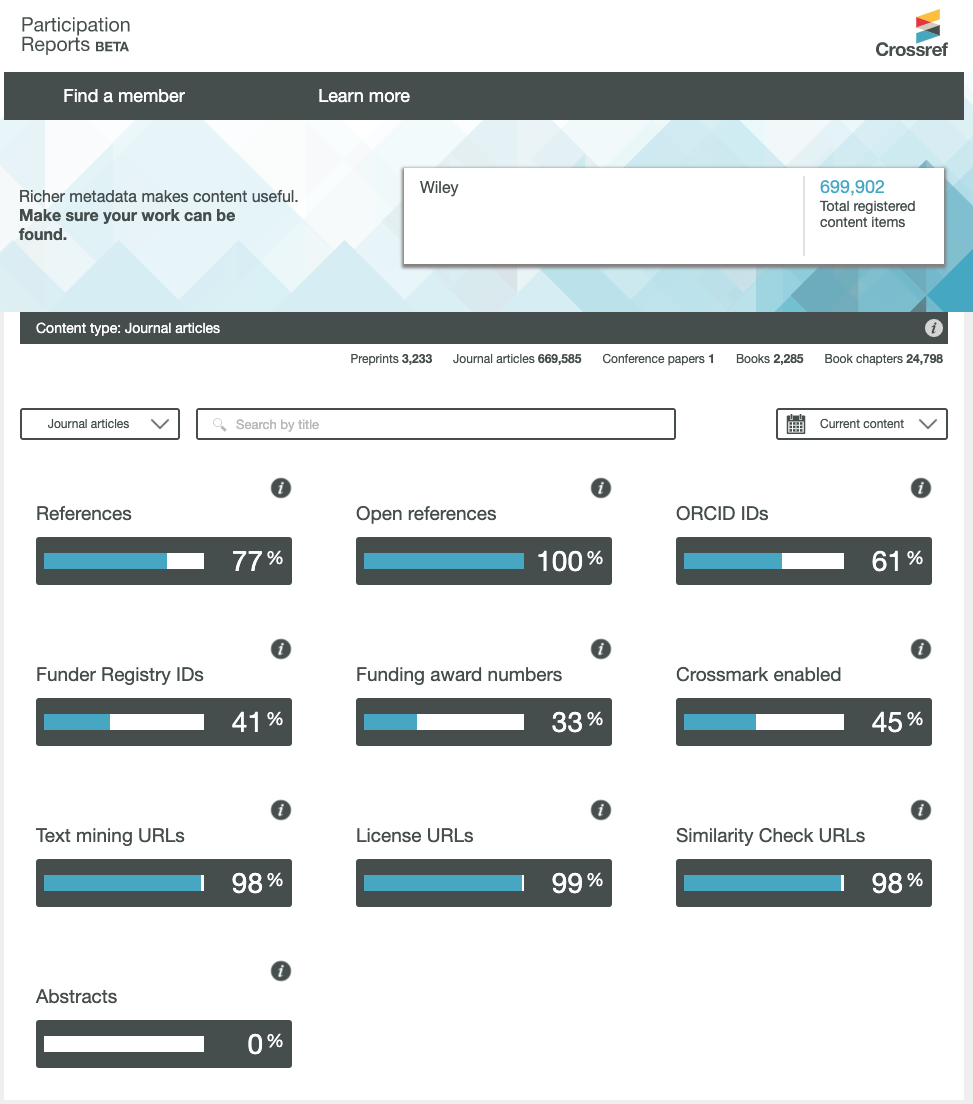
To date, 37.5 million works registered with Crossref have both full-text links and TDM license information. We continue to encourage all members to include full-text links and license information in the metadata they register to assist researchers with TDM. You can see how each member is doing via its Participation Report (e.g. Wiley’s).
Members are also making subscription content available for text mining (temporarily or otherwise) for specific purposes, such as to help the research community with its response to COVID-19. Back in April we highlighted how this can be achieved by including:
A “free to read” element in the access indicators section of publisher metadata indicating that the content is being made available free-of-charge (gratis)
An assertion element indicating that the content being made available is available free-of-charge.
To access Crossref’s click-through tool for text and data mining, users could log in via their ORCID iD. They could then review TDM license agreements posted by Crossref members and accept, reject or postpone their decisions until later. Having agreed to a publisher’s terms and conditions this action was logged against the user’s API token which they could use when requesting full-text from the publisher.
Since the pilot in 2014, only 2 publishers have continued with the tool and fewer than 300 API tokens have been issued.
Publishers have since developed their own mechanisms for managing TDM requests. The introduction of UK (2014) / EU (2019) copyright exceptions for TDM has significantly reduced the number of requests and at the same time, more and more content is published under an open access license.
Given the low take-up of the click-through by both publishers and researchers, its goals are no longer being met. Therefore we will retire the TDM click-through in December 2020. Until that date, it will still operate for the two publishers and various researchers who use it while they finish implementing their alternative plans.
Crossref will continue to collect member-supplied TDM licensing information in metadata for individual works, and researchers can continue to find this via the Crossref APIs.