Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
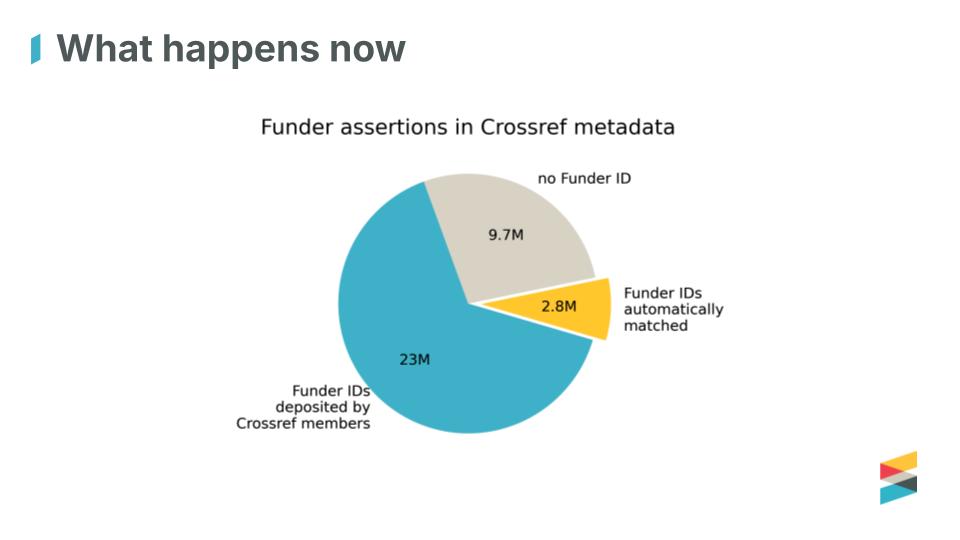
Funding is one of the key enablers of the research lifecycle, but has been one of the hardest parts of the scholarly record to identify, describe and connect. This is slowly changing as we have recently reached a very exciting milestone for Crossref’s Grant Linking System (GLS). What makes it remarkable is not only the numbers reached, but where the data comes from. Research funders, who joined Crossref as members, have actively contributed more than 200,000 grants to the Research Nexus (Figure 1).
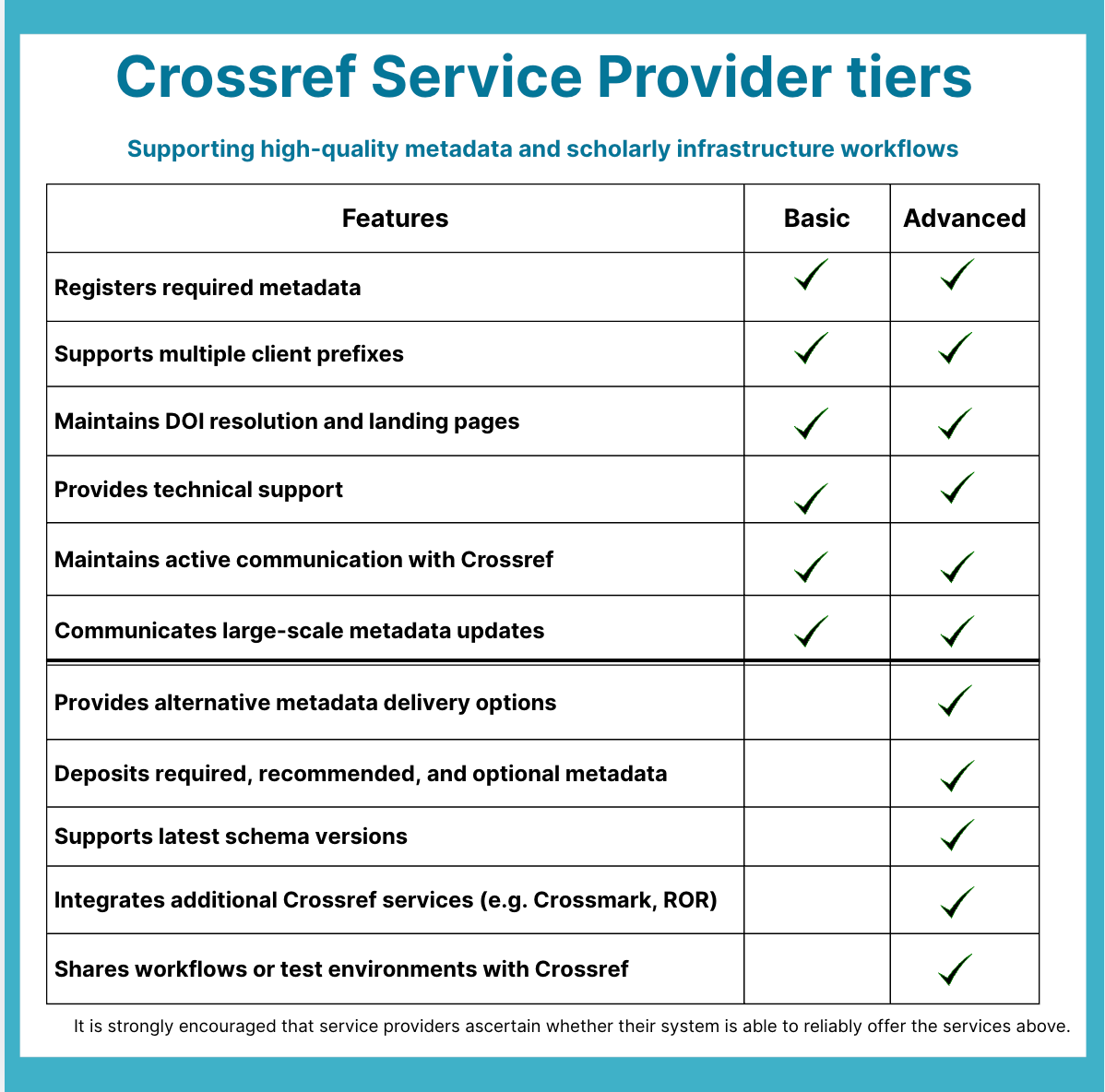
We are pleased to announce the re-launch of the Crossref Service Providers Program. From today, we are accepting applications from organisations providing tools for metadata registration to Crossref members. Participation in this program is free and the application involves an accreditation process to determine eligibility and the appropriate participation tier.
As a membership organisation, Crossref supports its members to provide rich and complete metadata which facilitates integrity judgements, increases discoverability, linking among scholarly objects and activities, and improves transparency. Service providers are key collaborators in this work because they enable our members to adopt better metadata practices.
Three years ago, we asked our members what they needed from Crossref’s metadata. We received confirmation that we were going in the right direction, as well as some new ideas to explore. This helped set the course for our metadata development work since then, and continues to guide where we’re headed next.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Operations, governance, and a growing membership
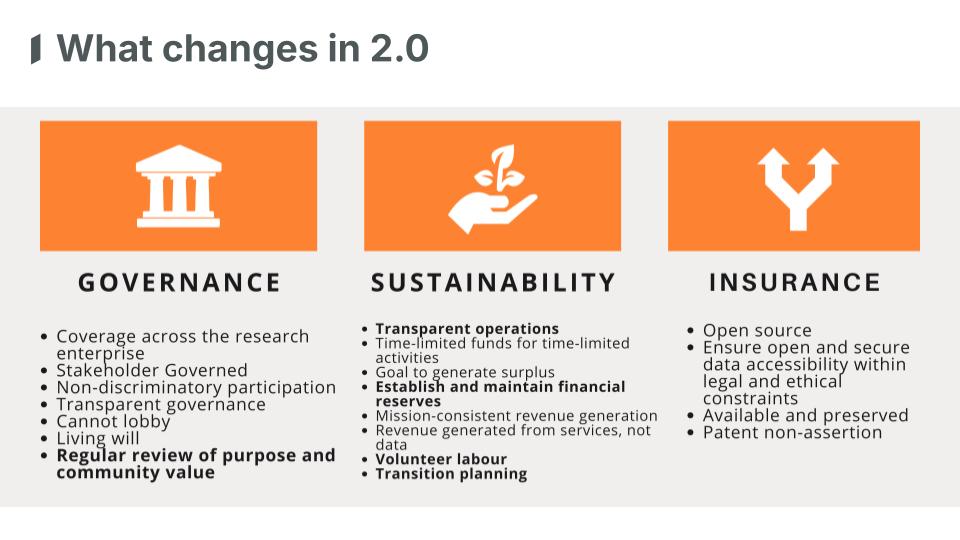
Our Chief Operating Officer, Lucy Ofiesh and Executive Director, Ed Pentz, opened each session with an update on operations and governance, starting with the Principles of Open Scholarly Infrastructure (POSI). We adopted POSI in 2020. Recently, the Principles were updated by a group of adopters, following a community consultation, and four new principles were added: periodic review of purpose and community value; transparent operations as a distinct principle; refined guidance on financial reserves; and attention to volunteer labour and transition planning.
Infrastructure organisations can use POSI to assess themselves and demonstrate to the community how they’re adhering to the principles, which support forkability, long-term sustainability, open assets, and transparent, community-led governance. We published a biannual report on how we measure up against them, so we’ll publish our next self-audit against the new set at the end of 2026, which is under discussion and preparation now.
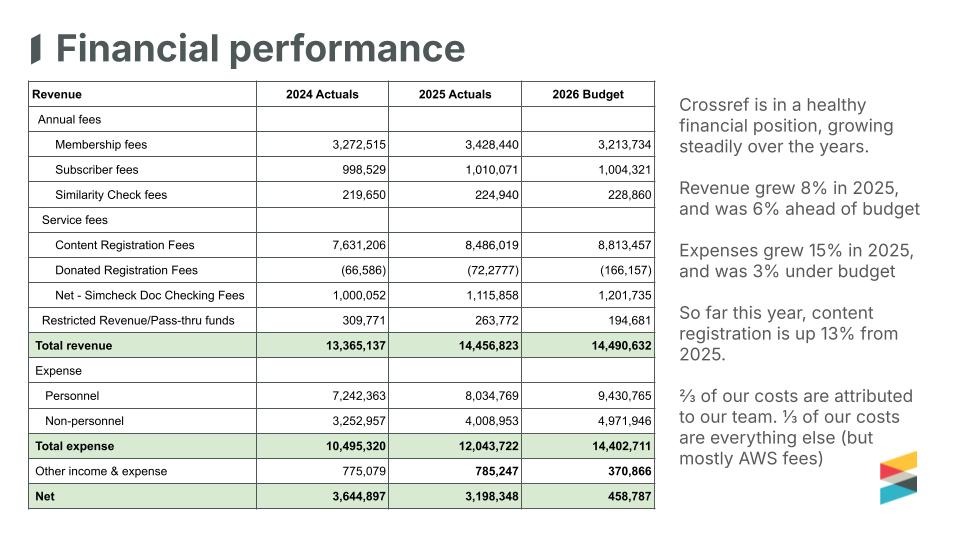
Financially, we’re in good shape. With so many new members joining every month, our revenue grew 8% last year, while expenses came in 3% under budget, and Content Registration was up 13% year-on-year at the end of March, well above our long-term average of around 7%. We’ve used our operating surplus to build up and maintain a reserve fund of 12-months of operating expenses, which matters for long-term sustainability. We use additional surplus funds beyond our reserves to reinvest in our mission and community.
If you’re a member and want a say in how we’re governed, the call for board nominations opened in May. Seven seats are up this year, one large and six small, and any member can stand. Voting runs for around five weeks, one vote per member, regardless of size. Last year, just 6% of members voted, and we’d like to see that increase. The call for expressions of interest is now closed for 2026, and candidates will be announced by our Nominating Committee in the coming months in advance of the election and annual meeting, which will be held on 22nd October 2026.
Robbykha Rosalien and Maryna Kovalyova from our membership team then took us through the membership picture. We’re now 25,000 organisational members from 167 countries, with around 51% based in Asia. The majority of our new members are universities, scholar-led publishers, societies, small journal publishers, and government agencies. We have help from 140 sponsoring organisations and 42 ambassadors, and we’re grateful for all the support they offer our members.
The metadata corpus and its use have grown alongside the community
Turning to new members, over 3,000 have joined from 142 countries since the last community update. 54% are from Asia, with Indonesia accounting for 17.5% of the total and India next at 9.5%. We continue to have members joining from the US and the UK, and we also have over 100 new members from Turkiye, with strong growth in Brazil and Pakistan as well.
January 2026 brought a major change with the introduction of a new fee tier for members with annual revenue or expenses (whichever is higher) of under USD 1,000. Since then, 40% of the new members joined under this new tier. 40% of our new members identify themselves as publishers and 40% as universities or scholarly organisations, with plenty of societies (13%), governmental agencies or NGOs (4%), and others, such as hospitals. The most popular publishing platform choice among the new members remains Open Journal Systems by PKP at 55%, with 30% saying they have no platform, and WordPress (4%) and Scholastica (2%) following. Notably, we’re working with PKP this year to help members transition to OJS 3.5, which supports richer metadata.
We also extended our Global Equitable Membership (GEM) program at the start of the year to include 18 additional countries. GEM offers Crossref membership and Content Registration without any fees. Since the last community update, we’ve gained our first members in Haiti, South Sudan, and Niger, and 20% of all independent members who have joined since then are GEM-eligible.
Introducing the Member Practices Working Group
Our Membership Director, Amanda Bartell, introduced our new Member Practices Working Group with a reminder of Crossref’s role in preserving the Integrity of the Scholarly Record (ISR). We’ve always aimed to keep barriers to membership as low as possible, because the best way to support a healthy scholarly ecosystem is to make metadata about published content as open and transparent as possible. That openness lets members demonstrate their practices through metadata, signalling trustworthiness to the scientific community as a whole, and when practices fall short, the metadata itself can surface those issues. Our member terms already make the importance of accurate metadata clear: if the community identifies inaccurate metadata, we can suspend or revoke membership. That is a last resort, and our first approach is always to contact the member, explain the problem, and work with them to get the metadata record corrected.
But what if the reports we receive from the community don’t relate to metadata, and instead to the member’s broader practices? This is an increasing issue, and it has been unclear how and when we should respond.
In consultation with our board, we updated our member terms last year and added an obligation for members to comply with a set of published member practices. The role of the working group is to draft this set of practices and provide clear guidelines on what we expect of Crossref members. In rare situations where issues can’t be resolved, the Member Practices will provide the basis for acting decisively, including suspending or revoking membership.
The Crossref Member Practices Working Group brings together differently sized members from different regions, metadata users, bibliometricians, and scholarly sleuths. Once drafted, we’ll take the Member Practices out for community consultation, with a board vote expected at their November meeting. It’s particularly important to us that the practices are achievable for all types of members, and we don’t want to create any extra barriers to entry or to continue membership for less experienced or less well-resourced members.
Crossref Member Practices Working Group:
Rene Aquarius, Radboud University
Guntram Bauer, Human Frontiers Science Program
Dorothy Bishop, University of Oxford
Gaelle Bequet, ISSN International
Oscar Donde, Pan Africa Journal
Jason Hu, Taylor and Francia and United2Act
Kihong Kim, Korean Council for Science Editors
Leslie McIntosh, Digital Science
Adya Misra, Sage Publishing
Katharina Reick, Austrian Research Council (FWF)
Leena Shah, DOAJ
Émilie Lavallée-Funston, University of Bristol and Co-chair of Transfer Standing Committee
Jennifer Wright, Cambridge University Press and COPE Council Member
Jiayi Xu, Bon View Publishing and COPE Council Member
The working group considered a few themes related to title-ownership disputes. They include making clearer the distinction between the journal owner and the journal publisher.
To seek feedback from the community on those emerging themes, Amanda ran two live polls during the call. One of her questions was: for the records you register with Crossref, are you the journal owner, the nominated publisher, or a bit of both? 45% of respondents said a bit of both, with the journal owner as the next most popular response, and the nominated publisher after that. The second poll asked whether the phrase “nominated publisher” accurately describes what those of you in that role do. The result suggested it is broadly acceptable, though we’d still like to hear how you’d phrase it if not.
Metadata schema
Patricia Feeney and Helena Cousijn from our programs and services team walked us through a year of schema work and what’s coming next. Schema 5.4 was released in March 2025 with three key features: typed citations, version numbers, and preprint status.
Typed citations give members the chance to indicate in the metadata what type of citation it is, so when an article cites a dataset, it’s now possible to explicitly say so. So far 23 DOI prefixes are using typed citations, so adoption is starting, and we’d really like to see it grow. If this is something you think is useful for you, please take a look, or reach out, and we’ll help you get started.
Version numbers, which 25 DOI prefixes now use and mostly for preprints, let you indicate different versions. We’re not yet seeing much use for articles or other record types, which we’d like to encourage. Notably, when you’re registering new versions of the same record, there’s no separate content registration fee, as long as you include the relationship in the metadata so our billing code can identify it as a version.
Preprint status lets you indicate that a preprint has been retracted or withdrawn, for example.
Earlier this year, we added the ability to include grant DOIs in funding metadata. When you register metadata for any research output, you can now include the persistent identifier to indicate which grant funded the work. As the number of grants registered as part of the Grant Linking System by our funder members grows (with now over 200,000 grant DOIs in existence), this dedicated new field provides an opportunity for members registering works resulting from the funding to unambiguously identify the grants that funded the work and to establish the connection between grants and the outputs—the entire goal of the global Research Nexus of multilateral relationships that we’re building. The grant DOI links to a full grant record, including funding type, project information, investigator details, funder and program/schema details, and institutional relationships.
We’re working on Schema 5.5. The main thing we know many of you have been waiting for is support for the CRediT taxonomy and its 14 contributor roles. We’re also enabling multiple roles for a single contributor, and within the Crossref vocabulary, which we still support, it will be possible to specify the corresponding author.
After 5.5 comes the update to our dedicated grant schema. Grant Schema 0.3.0 adds the ability to indicate that a grant was awarded to an institution (via a ROR affiliation ID), reflects that roles can change over time, and adds support for a persistent project identifiers, RAiD – a service that functions as a project identifier to indicate how a grant relates to one or more projects.
We’re also deprecating older schema versions. We’re supporting over 27 at the moment, which is too many and not helpful to members. The fundamental structures need updating, and we also need to tighten some of our requirements to obtain better and more complete metadata. We started the project at the end of last year, and we’ll be saying goodbye to a set of versions at the end of this year. Everyone using those versions has already been contacted, so if this concerns you, you should have heard from us. The project continues over the coming years, and we’ll work on deprecating other Schema 4 versions, so that by the end, we’ll only be supporting the different Schema 5 versions and the upcoming Schema 6. We’ll notify everyone impacted and let you know how to transition.
Once 5.5 and the grant schema are out, we’ll start working on remodelling contributor names, which is a really big project. A proposed model was circulated for feedback in May. The same update will also work on statements, currently for funding, acknowledgments, ethics, accessibility, AI use, data availability, copyright, and conflict of interest.
Tools and demos
Funder matching, rebuilt around ROR
Dominika Tkaczyk and Jason Portenoy from our technology and data science team gave an update on the Metadata Matching work, framed around the vision of the Research Nexus: a rich and open network of relationships connecting organisations, people, outputs, and activities within the scholarly record. First up for the project is funder matching, and Dominika and Jason took us through the new methodology and progress on implementing the work.
Funding metadata involves three main entities: funders, grants, and research outputs. Organisations are identified by Open Funder Registry (OFR) IDs or ROR IDs, and research grants and outputs have DOIs. These entities should be linked in order for provenance and attribution to be determined, which is important for evidence but also for things like research assessment and compliance.
The three entities: Funding and academic organisations→recipients are awarded grants→ repositories and publishers support outputs.
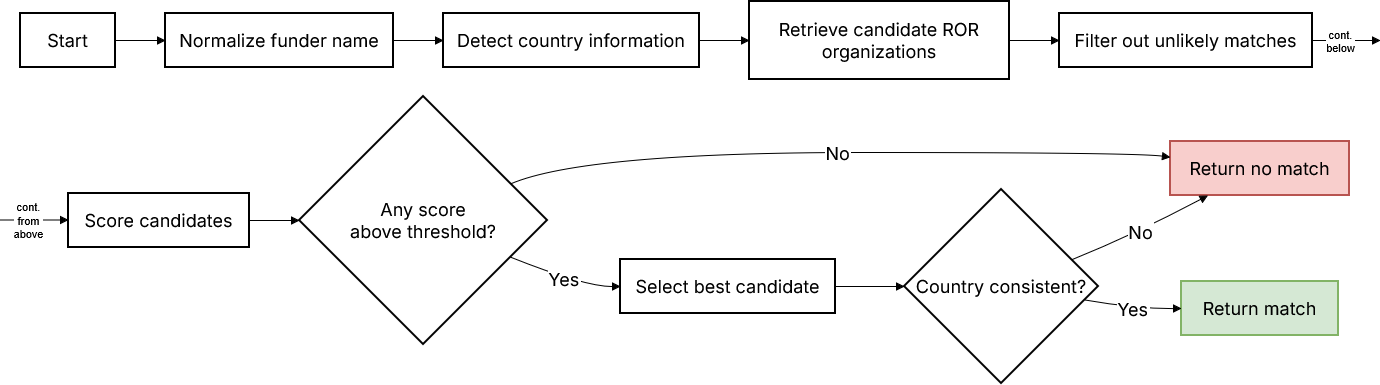
In practice, many of those relationships are missing when metadata is deposited. The new Crossref funder matching identifies the funding organisation from the name in the metadata and, when successful, inserts the correct organisation identifier, disambiguating the relation between the research output and its funder. Applying matching over the years has added around 2.8 million funder identifiers to records, shrinking the gap.
So why rebuild what we already have? Two reasons. We’re committed to supporting ROR more deeply across our services, and as part of that, we want to switch to ROR IDs as the main identifier for funders. Second, our current funder matching is part of our legacy system, which lacks transparency, thorough evaluation, or flexibility.
The new strategy is part of our metadata matching project. The core architecture is built, and the new strategy has been tested; we’re now adding features such as sending redeposits, with more testing later this quarter and a release aimed for around the middle of the year. After that, we’ll move on to a grant-matching workflow to link outputs to grant records where that link is missing.
They closed with a live demo covering four cases. Starting with a simple example of Wellcome, which matched cleanly because the input name matched the official organisation name exactly, they then moved on to more complex examples, showing increasing discrepancies between the input and the name variant in ROR, yet the strategy still resolved it. However, some names are not possible to match in this way, such as the “Faculty of Arts and Social Sciences,” which is a very generic name that many organisations might use as part of their structure. That matters too: the strategy recognises when no match should be returned, limiting the level of incorrect information that might be introduced into the metadata.
Data citations API endpoint
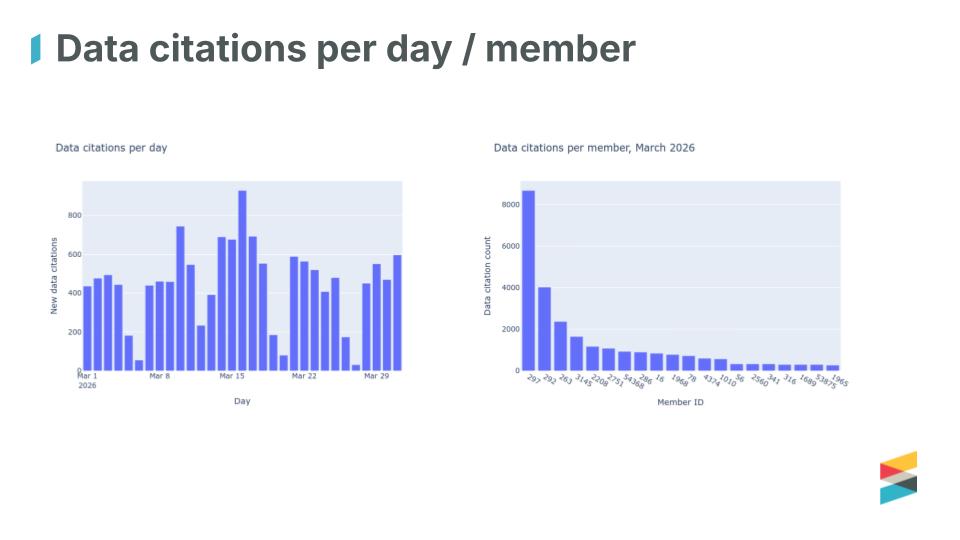
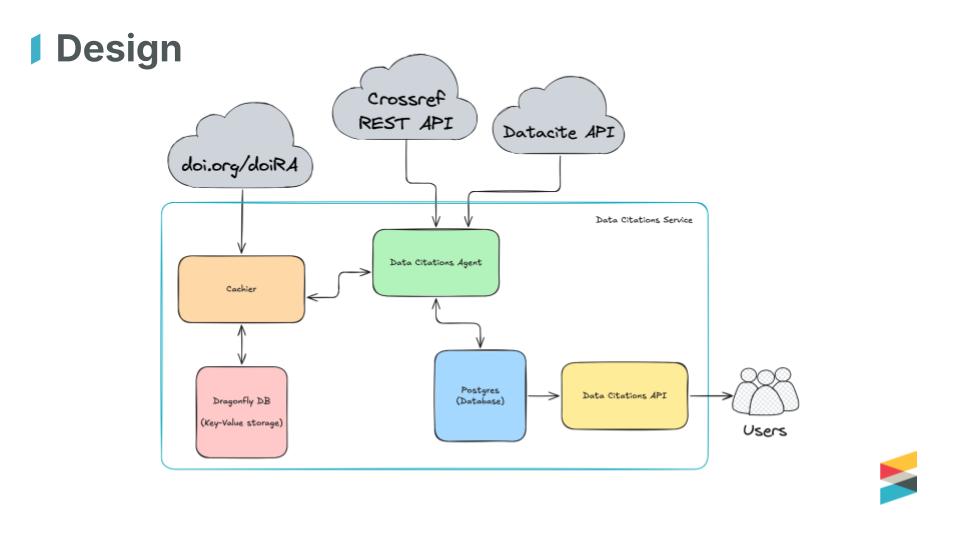
Martyn Rittman who heads up our Research Nexus development, and Panos Pandis from our technology team introduced the new data citations API endpoint. It exposes data citations from deposited metadata, with over 700,000 included so far. Among all the reference information we hold, individual data citations are difficult to pick out, and there’s a specific community interest in them, so we’ve put them together and made them available through a dedicated API.
Data citations can be included in two parts of a metadata record: references and relationships. We look for links to datasets registered with a Crossref DOI or a DataCite DOI. Documentation can be found here.
Through March 2026, we typically collected 400 to 600 data citations per day, with some variation, especially on weekends. The new endpoint is still in beta, and we invite feedback: is it useful, what would make it more useful, and what should we do next? Let us know on the forum.
Metadata Manager: new content types coming
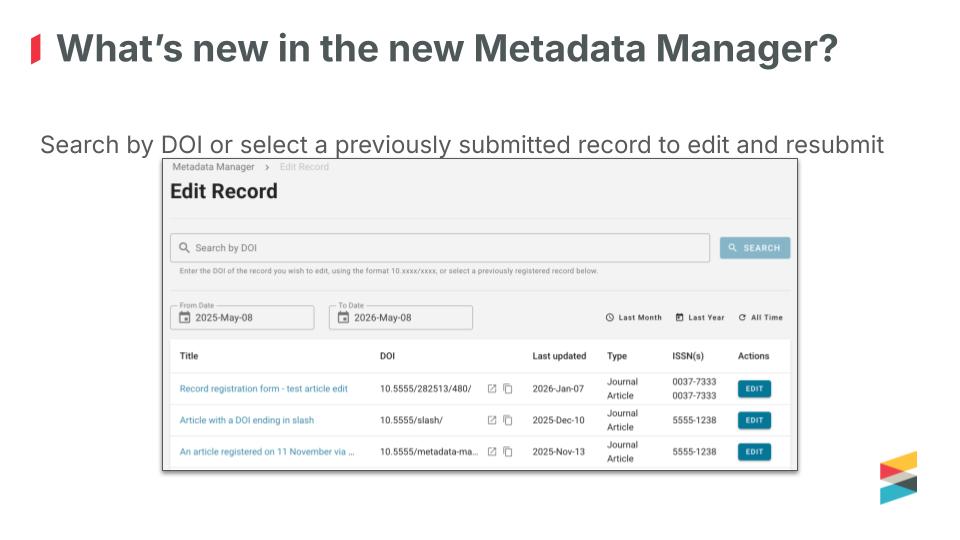
Lena Stoll, who heads up our community trends program and Patrick Vale from technology took us through Metadata Manager. We retired the legacy interface at the end of last year and replaced it with a more modern and flexible helper tool for record registration. It’s already in use by an increasing number of members for grants and journal article records.
A recent addition is a search field, where you can enter the DOI of any supported record (currently a journal article or a grant) and edit it directly, if you have permissions. We’ve also added fields to the journal article registration form to include relationship metadata, which is key to building the Research Nexus.
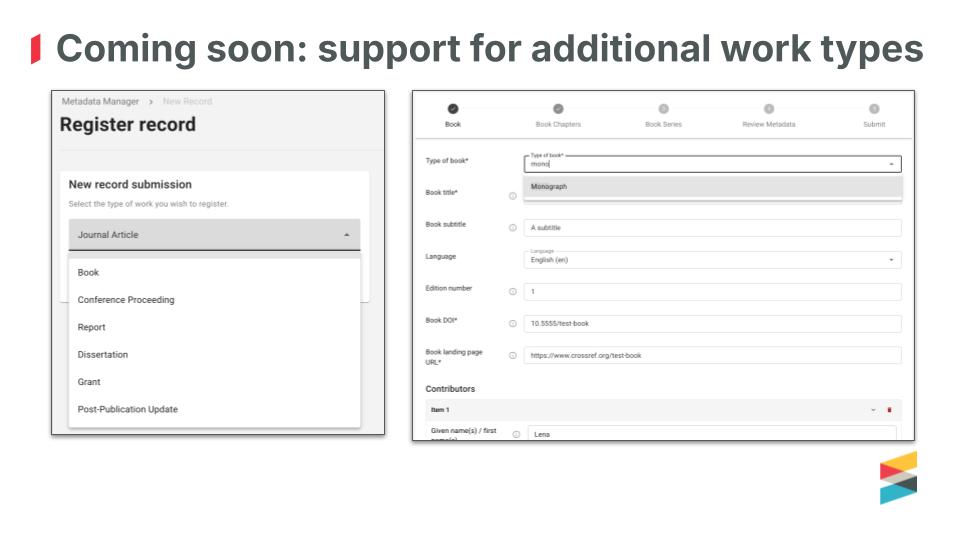
Plenty more is coming. The new Metadata Manager will expand to support books and chapters, conference proceedings, reports, dissertations, and post-publication updates over the next few months. The interfaces follow a similar workflow: a page or two of work-level metadata, optionally chapter, or paper, or series metadata if applicable, a review step, and submission. We want to keep them as simple and usable as possible.
We hope that the post-publication update form will be welcomed by our members, as it will enable registration of retractions, corrections, and expressions of concern without any knowledge of XML. Lena and Patrick walked through a live demo of a retraction notice end-to-end. The system checks that the DOI being retracted exists, and any errors surface right away rather than later by email. We’re collecting feedback on the new tools on the forum.
The team also shared an update for institutions that use DSpace – its next version (version 10), will include a Crossref integration that lets you register Crossref metadata and DOIs automatically for content such as dissertations hosted in your DSpace repository.
Looking ahead
A new Service Providers Program
Madhura Amdekar shared our plans to launch a new version of the Crossref Service Providers Program later this year. Service providers are hosting platforms, manuscript submission systems, XML or metadata providers, and general publisher service organisations that work with our members to create, register, or display metadata on their behalf. They’re key partners in promoting metadata best practices, and we’re looking forward to collaborating with these organisations more closely. The program will not charge any fees; it will offer certification in two tiers, depending on the depth of integration with Crossref services.
Service providers commit to staying up to date with Crossref services and policies, sharing feedback, providing information about their service offerings and metadata workflow documentation, promoting metadata best practices, making reasonable efforts to accommodate changes to our schema and other services, and ensuring that clients’ DOIs continue to resolve to relevant content and landing pages.
We’d really like to hear from you: which service providers in this space would you like to see as part of the new program? Drop suggestions on the forum or get in touch with us directly.